

Auto-scale Kubernetes pod với custom metrics cho MQTT broker
 By Phạm Thanh Long
By Phạm Thanh Long- Development
- 10/09/2024
- 5 minutes read
- 6,000 Views
Như ta đã biết, Kubernetes sử dụng Horizontal Pod Autoscaler (HPA) để có thể scale số lượng pod. Để có thể làm được điều đó, HPA sẽ thực hiện vòng loop để query những metrics hiện tại sau đó tính toán và thực viện công việc scale.
Nhưng có vấn đề đặt ra ở đây, đó là đôi khi những metrics thu về được lại chưa đủ để có thể thực hiện scale. Ví dụ sẽ được nói đến tiếp theo trong bài viết.
>> Tìm hiểu thêm về: Kubernetes là gì? Vai trò và các thuật ngữ phổ biến
Để thực hiện điều này thì Kubernetes có thành phần được gọi metrics registry. Mục đích metrics registry là cung cấp giao diện để client có thể query metrics. Giao diện này gồm 3 thành phần là:
Resource Metrics APICustom Metrics APIExternal Metrics API
Vậy khi chúng ta muốn scale với Custom Metrics API, ta cần phải cung cấp backend cho nó. Backend này bao gồm 2 thành phần chính đó là Metric collector và Metric API server.
METRIC COLLECTOR
Chúng ta sẽ lựa chọn Metric collector khá phổ biến: Prometheus
Để cho đơn giản,ở đây ta sẽ sử dụng Prometheus-operator thông qua Helm:
Repo prometheus-operator:
https://github.com/helm/charts/tree/master/stable/prometheus-operator
Prometheus-operator gồm nhiều thành phần, trong đó chủ yếu là Prometheus, Grafana (công cụ tạo dashboard), và các service monitor để lấy metrics từ kubernetes.
Câu lệnh:
helm install my-mon stable/prometheus-operator -f values.yaml
Trong đó values.yaml là file mình tự tạo với nội dung như sau:
serviceMonitorSelectorNilUsesHelmValues: false [1]
Việc này là cần thiết vì nó sẽ cho phép thu được những metrics khác ngoài những thành phần của Kubernetes.
Sau khi thực hiện xong, ta hoàn toàn có thể truy cập trang web đã được host lên:
Prometheus:
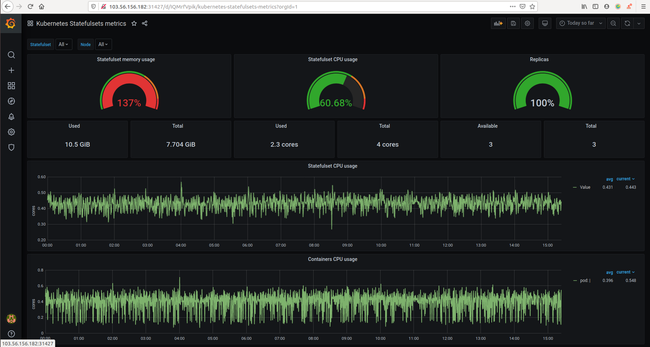
Grafana:
MQTT BROKER (VerneMQ)
Ta sẽ sử dụng VerneMQ làm MQTT Broker làm ví dụ
>> Tìm hiểu thêm về: MQTT là gì? Giao thức truyền thông điệp theo mô hình cung cấp/ Thuê bao
Tiếp tục sử dụng Helm để tải VerneMQ
Repo:
Ta cần phải cấu hình VerneMQ 1 chút mới có thể chạy được không như Prometheus-operator.
helm pull vernemq/vernemq --untar true
Ta sẽ pull Chart về và giải nén, ta có thư mục vernemq
Truy cập file values.yaml trong thư mục, ta chỉnh sửa 1 số thông số như sau
Quan trọng
Vì helm sử dụng image 1.10.2 để tạo vernemq và image này bị lỗi thiếu thư viện, ta cần chỉnh config
image: 1.10.2 thành image: 1.10.2-1-alpine hoặc image: lastest để không gặp lỗi này
Sau đó:

Tạo ra service monitor để prometheus lấy được những metrics
Đồng thời ta cần phải thêm vào:

Để bỏ qua bước xác thực khi truyền tin

Chấp nhận điều khoản sử dụng của VerneMQ [2]
Ngoài ra, VerneMQ còn là 1 Stateful Cluster thế nên ta cần phải lệnh gọi để tách node khỏi cluster khi scale down.
Trong thư mục templates, ta truy cập file statefulset.yaml thêm nội dung:

Sau khi cấu hình xong, ta sử dụng helm để triển khai:
helm install myVerneMQ . --set replicaCount=2 -f values.yaml
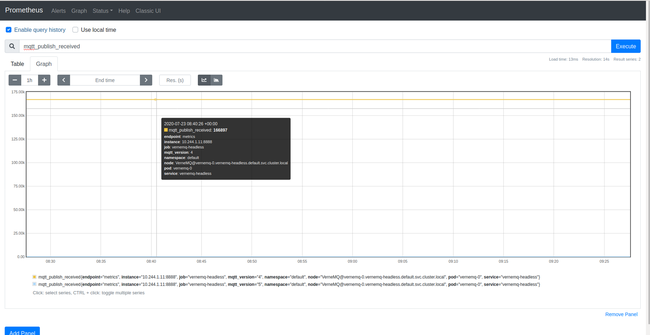
Sau khi triển khai xong, thì Prometheus cũng có thể lấy được metrics từ VerneMQ (VerneMQ có exporter mặc định khi được tạo ở port 8888) [3]
Để kiểm tra hoạt động monitor đúng, ta sẽ thử publish message đến
Ở đây ta sẽ sử dụng Python và thư viện paho-mqtt
paho-mqttMQTT version 3.1.1 client classPyPI
Code python:
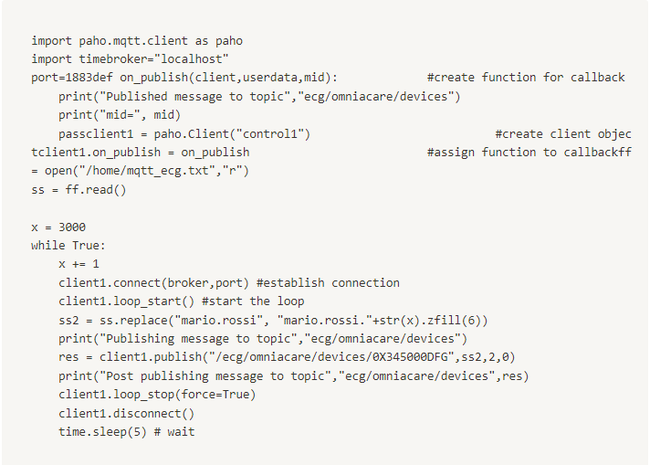
time.sleep(5) để điều khiển tần suất bắn message
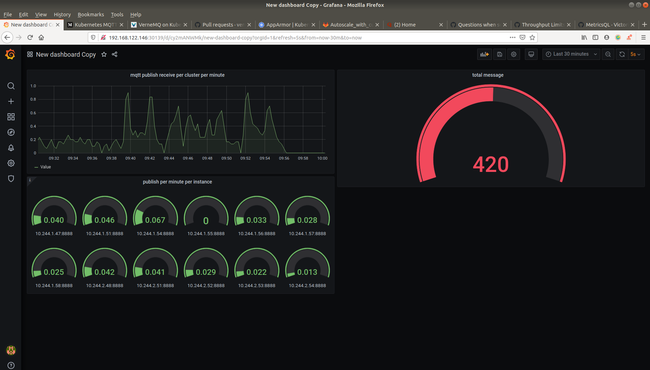
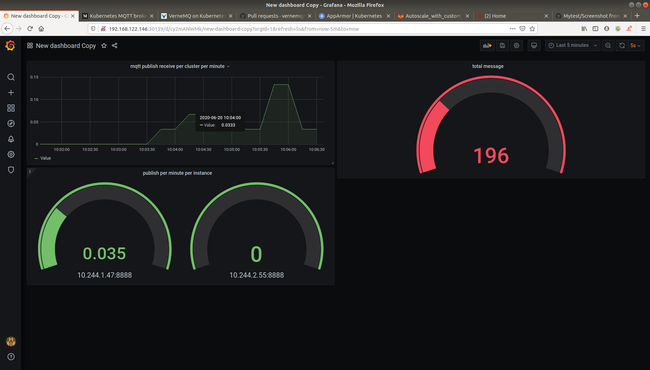
Ta sẽ tạo dashboard sử dụng grafana
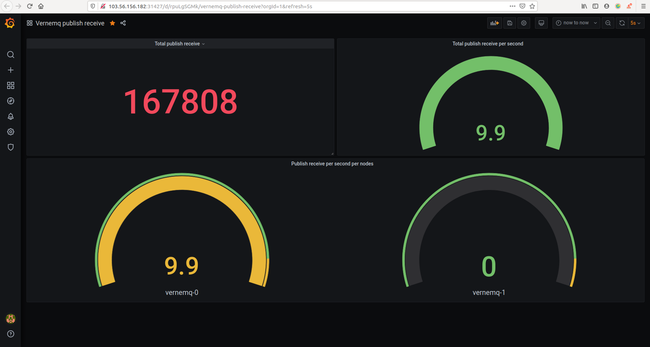
Trong đó:
Total publish receive: sum(mqtt_publish_received)
Total publish receive per second: sum(irate(mqtt_publish_received{mqtt_version="4"}[1m]))
Publish receiver per second per node:
irate(mqtt_publish_received{mqtt_version="4"}[1m])
Ở đây, ta muốn cho VerneMQ scale theo số lượng message publish mỗi giây, nhưng lại không có metrics nào đáp ứng được nhu cầu của chúng ta cả.
Và như đã nói ở trên, chúng ta cần Metric collector và Metric API server, ta sẽ cần Metric API server. Ở đây chúng ta sử dụng Prometheus-adapter
METRIC API SERVER
repo :
https://github.com/helm/charts/tree/master/stable/prometheus-adapter
Tương tự như VerneMQ, ta cũng cần pull về cấu hình 1 số chỗ
Trong file values.yaml

Ta trỏ đến prometheus operator

Ta tạo custom rule để biến metrics mqtt_publish_received
trở thành tổng số message nhận được mỗi giây trên mỗi node
sum(irate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
Sau đó khởi tạo prometheus-adapter
helm install prom-adap . -f values.yaml
Tạo autoscale và kiểm tra
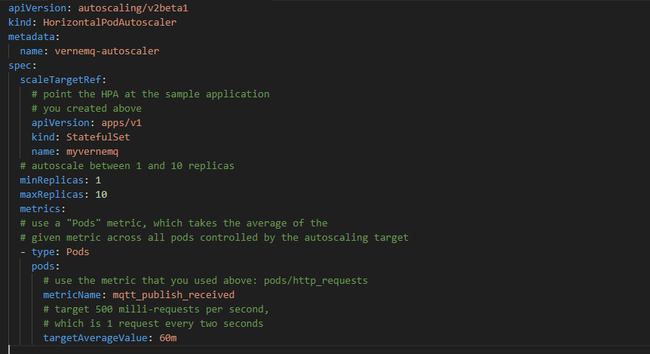
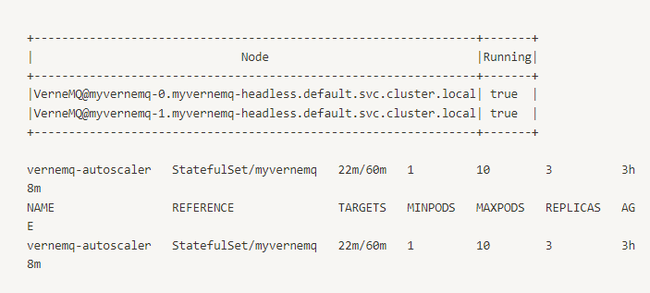
Ban đầu khi không chạy stress test:
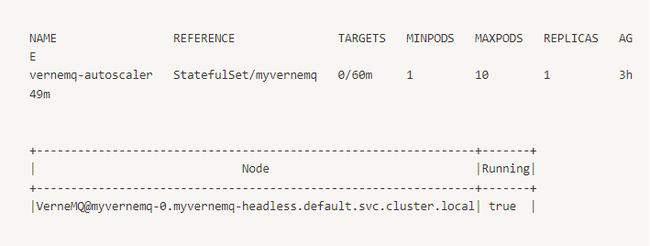
Khi tải tăng lên:
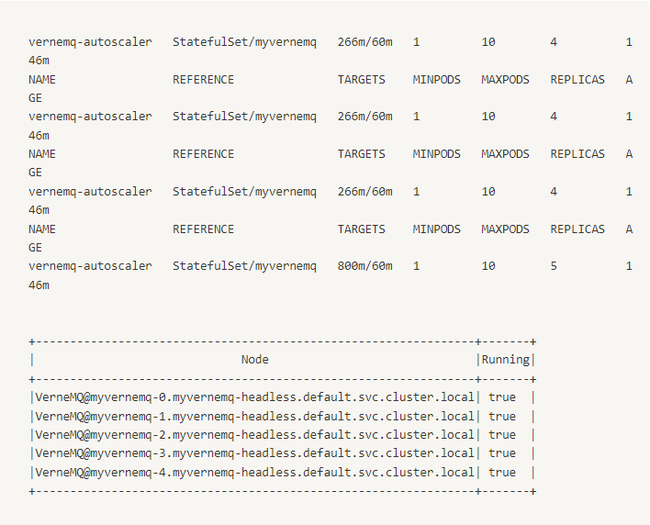
Tiếp tục tăng:
Sau cùng:
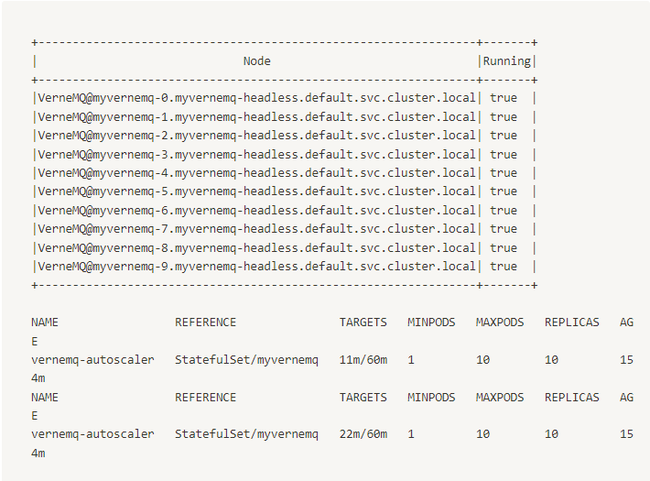
Ta theo dõi vào TARGETS có thể thấy pod được scale khi request đến nhiều hơn, và scale vào khi ít request đi.

Phạm Thanh Long
Pho Tue SoftWare Solutions JSC là Nhà Cung cấp dịch Trung Tâm Dữ Liệu, Điện Toán Đám Mây Và Phát Triển Phần Mềm Hàng Đầu Việt Nam. Hệ Thống Data Center Đáp Ứng Mọi Nhu Cầu Với Kết Nối Internet Nhanh, Băng Thông Lớn, Uptime Lên Đến 99,99% Theo Tiêu Chuẩn TIER III-TIA 942.
Kommentar hinterlassen
Ihre E-Mail-Adresse wird nicht veröffentlicht. Erforderliche Felder sind mit * markiert